Journal of Machine Intelligence and Data Science (JMIDS)

Volume 5 - Year 2024 - Pages 46-53
DOI: 10.11159/jmids.2024.006
An Integrated Framework for Automated Web Scraping and Sentiment Analysis of Product Reviews
Rosa Arboretti1, Manuel Barusco1, Elena Barzizza1, Nicolò Biasetton1, Riccardo Ceccato1, Davide Ferro1, Luigi Salmaso1, Giacomo Vezzosi1
1University of Padova, Department of Management Engineering, 3 Stradella San Nicola, 36100, Vicenza, Italy
rosa.arboretti@unipd.it; manuel.barusco@studenti.unipd.it; elena.barzizza@phd.unipd.it ;
nicolo.biasetton@unipd.it; riccardo.ceccato.1@unipd.it; davide.ferro@unipd.it; luigi.salmaso@unipd.it;
giacomo.vezzosi@studenti.unipd.it
Abstract - In the digital age, online product reviews play a pivotal role in influencing consumer choices. This paper presents an innovative tool that combines state-of-the-art natural language processing and sentiment analysis technique with ChatGPT technology. The tool enables automated web scraping and comprehensive sentiment analysis of product reviews, with a focus on aspect-based sentiment analysis and document-level sentiment aggregation. Our tool employs ChatGPT, a powerful language model, to conduct aspect-based sentiment analysis, extracting nuanced sentiments related to specific product attributes. This provides a granular understanding of consumer opinions. The tool also integrates advanced models for document-level sentiment analysis, enabling the aggregation of overall sentiment scores from multiple reviews. The framework comprises three main components: Web Scraping Module: this automates data collection from two major e-commerce platforms ensuring systematic extraction of reviews and metadata. Aspect-Based Sentiment Analysis Module:n leveraging ChatGPT, it categorizes opinions as positive, negative, or neutral and identifies specific product attributes. Document-Level Sentiment Analysis Module: this component provides an overall sentiment rating for the product. The tool can find applications in business, research, and consumer decision-making, allowing real-time product performance monitoring, market studies, and informed purchase decisions. Our integrated framework offers a robust solution for understanding and responding to consumer sentiments in online product reviews. By combining aspect-based and document-level sentiment analysis with ChatGPT's capabilities, it facilitates comprehensive insights into the digital marketplace.
Keywords: ChatGPT, webscraping, sentiment analysis, NLP.
© Copyright 2024 Authors - This is an Open Access article published under the Creative Commons Attribution License terms. Unrestricted use, distribution, and reproduction in any medium are permitted, provided the original work is properly cited.
Date Received:2023-11-16
Date Revised: 2023-02-16
Date Accepted: 2024-05-31
Date Published: 2024-08-23
1. Introduction
The global e-commerce landscape has undergone a paradigm shift in recent years, with online shopping becoming an integral part of everyday life for millions of consumers. As the volume of e-commerce platforms and user-generated content (UGC) grows exponentially, there is a pressing need for advanced analytical tools that can extract meaningful insights from the vast repository of online product reviews. In this era of information overload, the combination of web scraping techniques and state-of-the-art natural language processing (NLP) models is emerging as a powerful solution, enabling businesses to harness the power of consumer sentiment for enhanced decision-making.
In the early 2023 the Artificial Intelligence (AI) world has seen the widespread attention being captured by a significant advancement with the emergence of OpenAI’s ChatGPT, an advanced chatbot product trained on the Generative Pretrained Transformers (GPT) architecture with reinforcement learning from human feedback (RLHF) [1-2], designed to generate human-like conversations. GPT (3.5 and then 4), revolutionized the approach in artificial intelligence to human-model interaction and provided valuable power to be exploited. This paper delves into a ground-breaking approach for e-commerce review analysis, featuring the innovative use of the OpenAI ChatGPT API. By integrating web scraping technology with ChatGPT, we aim to propose a tool that address a pivotal challenge in the e-commerce domain: the extraction and interpretation of consumer sentiment at a granular level, focusing on specific aspects and attributes of products and services. an various pre-match activities based on the estimated attendance, and they can also calculate the precise number of staff and security personnel needed for the game.
Sentiment analysis, often also referred to as Opinion Mining, is a task of Natural Language Processing (NLP) that aims to computationally identify and categorise opinions expressed in a piece of text to determine the writer’s sentiments towards a particular topic, product, service [3-4]. With respect to the challenge of providing businesses with focused insight into customers’ perception of products’ or services’ features, aspect-based sentiment analysis (ABSA) results to be a suitable methodology to exploit. ABSA allows us to identify not just a review’s polarity (whether it is positive or negative) but also the polarity of the opinion on single aspects expressed within the review: it is possible to pinpoint the exact facets of the product or service that are praised or criticized, providing invaluable insights for product improvement, marketing strategies, and customer service enhancement. In the following sections, we will elucidate the methodologies involved in our approach, explore the potential benefits for e-commerce businesses, and present real-world case studies to demonstrate the effectiveness of our approach in extracting nuanced consumer sentiment. Moreover, we will highlight the significance of the GPT model in this context, showcasing its role as a versatile and powerful tool for NLP tasks and sentiment analysis. By the end of this paper, readers will gain a comprehensive understanding of how web scraping and aspect-based sentiment analysis, powered by OpenAI's ChatGPT, can be leveraged to unlock the full potential of e-commerce data, ultimately providing a competitive edge in the online marketplace. The paper is structured the following way: Section 2 reports a brief literature background on the field; Section 3 reports a full description of the materials and methods adopted in the tool development and in the case study application describing the webscraping techniques, the aspect-based sentiment analysis performed with ChatGPT and the model-based sentiment analysis. After the case study application of Section 4, in Section 5 a brief discussion and the conclusions.
2. Related Work
Sentiment analysis (SA), also known as Opinion Mining, is a Natural Language Processing (NLP) task focused on computationally identifying and categorizing opinions expressed in text to understand the author's feelings about a particular subject, product, or service (Liu, 2020; Chaturvedi, Cambria, Welsch, & Herrera, 2018). Over the last 15 years, the surge in UGC on the internet has propelled sentiment analysis into the spotlight due to its broad range of applications across various industries such as marketing, customer service, finance, politics, and social media. Furthermore, sentiment analysis finds application in the examination of moods, thoughts, and nuanced emotions conveyed in textual content (Özen & Özgül Katlav, Aspect-based sentiment analysis on online customer reviews: a case study of technology-supported hotels, 2023). This surge of interest has made sentiment analysis one of the most active research areas, as indicated by the substantial increase in articles dedicated to sentiment analysis and opinion mining (refer to (Birjali, Kasri, & Beni-Hssane, 2021)).
Sentiment analysis techniques are primarily categorized based on two factors: the scope of text being analysed and the algorithmic approach employed. In terms of the scope of analysis, sentiment analysis can be categorized into Document-level SA (Wilson, Wiebe, & Hoffmann, 2005), Sentence-level SA (Meena & Prabhakar, 2007) and Aspect-based SA (Jo & Oh, 2011). In document-level sentiment analysis, the primary objective is to determine the overall sentiment of an entire document or piece of text. This entails classifying the entire content as positive, negative, or neutral, based on the emotional tone conveyed throughout the document. This approach provides a high-level summary of the sentiment expressed in the text, without delving into finer-grained details within sentences or specific aspects. In sentence-level sentiment analysis, the focus shifts to assessing the sentiment of individual sentences within a document. This approach offers insights into variations and shifts in sentiment within the text, capturing nuances that might be less apparent in a document-level analysis. Aspect-based sentiment analysis takes it a step further by concentrating on the sentiment expressed toward specific aspects, features, or entities mentioned in the text. The goal here is to identify the sentiment associated with various attributes or components discussed in the document. This approach is particularly valuable for product reviews, where customers express different sentiments regarding different aspects of a product (e.g., battery life, design, performance). Each level of sentiment analysis comes with its unique advantages and applications. Document-level analysis provides an overarching sentiment summary, sentence-level analysis captures sentiment fluctuations within the text, and aspect-based analysis offers in-depth insights into specific attributes or features. Depending on the analysis objectives and the desired level of detail, researchers and practitioners can choose the most suitable level for their specific use case.
Concerning the algorithmic approach used for Sentiment Analysis, there are three main methodologies to consider (as per (Birjali, Kasri, & Beni-Hssane, 2021)) are Machine-Learning based, Lexicon-based, and Hybrid approaches.
Machine Learning approach employs supervised classification algorithms (SVM, Na¨ıve Bayes, Classification trees and more recently, deep learning models like Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and transformer-based models like BERT) to build a classifier that can identify text that expresses sentiment and classify text into positive, neutral o negative. Lexicon based approach is the most common because of its ease of implementation. This approach to SA requires the identification of a lexical resource called sentiment lexicon, or opinion lexicon, which is a predefined list of sentiment words associated with their semantic orientation with a positive or negative score [10-11] and a sentiment value is assigned to each token of the document for which a match with token in the lexicon exists. Focusing on the aspect-based sentiment analysis (ABSA) technique, in literature it has been broadly categorized both into machine learning and lexicon-based approaches (Jo & Oh, 2011). A significant challenge in sentiment analysis concerns the so-called domain: considering for example the task of performing sentiment analysis on customer reviews we should consider that there are many different categories of product that can be reviewed as laptops, books, hotels, restaurants. These categories can be addressed as domains and each one has its unique characteristics that should be encompassed within the model used to extract the sentiment of reviews in that domain. Practically a model trained on a particular domain will perform worse in another one. Considering dictionary-based model, words or terms used in domain-specific dictionaries may not have the same meaning in two different topics and/or contexts (Bagherzadeh, Shokouhyar, Jahani, & Sigala, 2021). Therefore, variations between domains pose a significant challenge in emotion extraction (Ruder, Ghaffari, & Breslin, 2016). Studies like [14-16], indicate that the ABSA is a suitable technique for analysing customer comments.
Considering the application of ChatGPT in the research field, as reported by (Kocoń, et al., 2023), after the launch of ChatGPT, the majority of subsequent publications primarily centered on tasks such as question answering and summarization. Additionally, other tasks, such as humor identification and generation (Chen & Eger, 2022), machine translation (Jiao, Wang, Huang, Wang, & Tu, 2023), sentiment recognition (Tabone & De Winter, 2023), paraphrasing (Aydın & Karaarslan, 2022), and various subtasks related to text generation, were also subject to analysis and investigation. (Kocoń, et al., 2023) pointed out that, while the performance of ChatGPT model is significant in many fields, it generally does not outperform the state-of-the-Art models. An exception is represented by the sentiment analysis field, as shown by (Amin, Cambria, & Schuller, 2023) which suggests it is a significant area for further research. Furthermore, there are two recent papers that showcase the use of GPT models for sentiment analysis in Italian (Castillo-González, 2023) and Arabic [24] languages. This underlines the significance of exploring emotion-related tasks as a particularly compelling area within the realm of NLP tasks, especially concerning GPT models.
3. Materials and Methods
The present section will describe in detail the procedures applied to extract product reviews from the web, extract aspects and sentiment for each review with ChatGPT, summarizing the results, extracting global sentiment of the document, and comparing the one obtained with ChatGPT to the one of a state-of-the-art model. Specifically, we built a tool for product reviews scraping and analysis. Such tool in the form of a web app, once identified a product, automatically scrape reviews of such product published on Amazon’s and Walmart’s website using different approaches. Once scraped, the reviews are automatically analysed using ChatGPT API and other state of the art models. A graph of the flow followed by the webapp is reported at Figure 1.
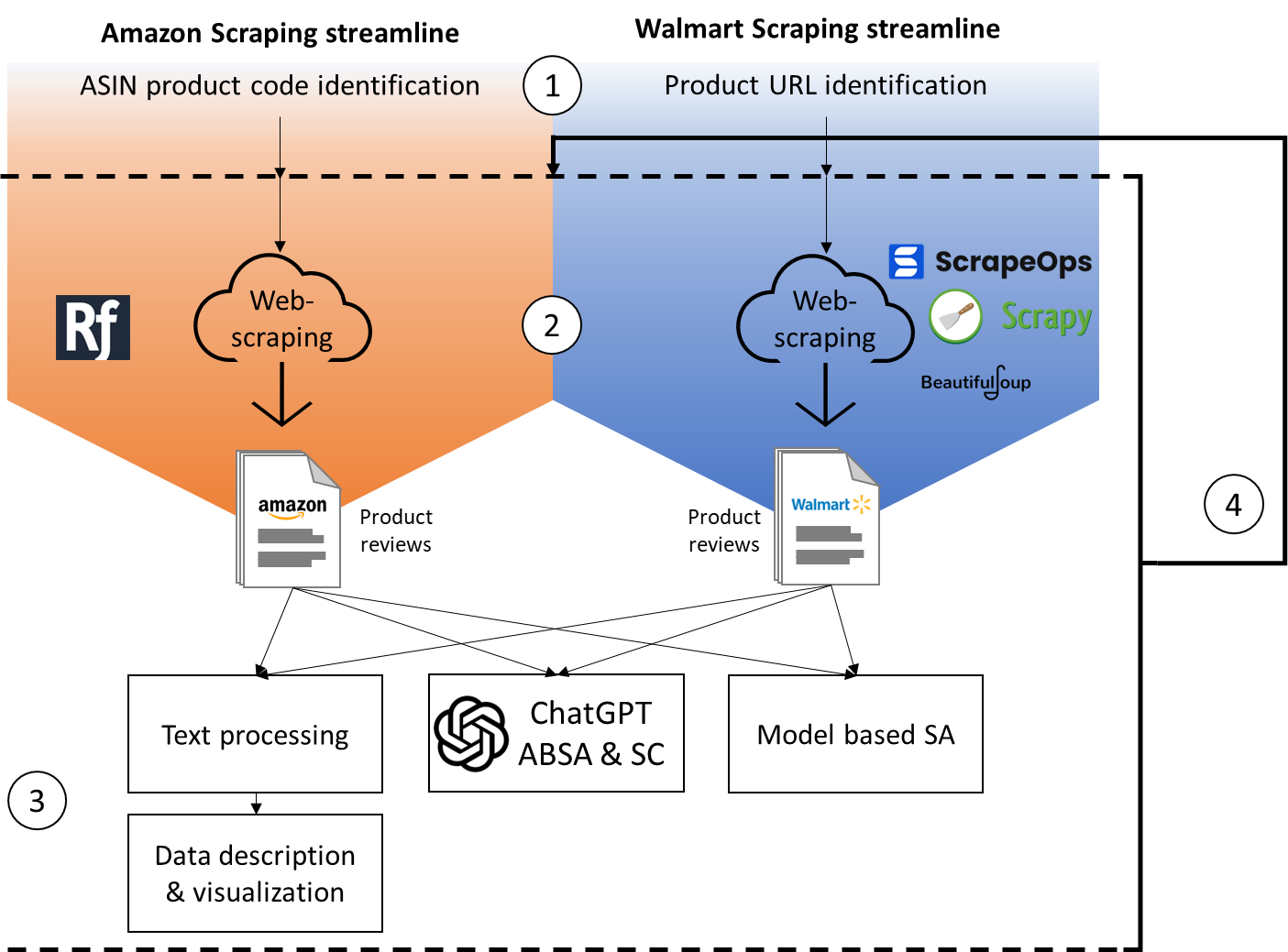
The process firstly consists of a product identification phase that distinguishes items via ASIN codes on Amazon and product URLs on Walmart. Following this, a web scraping procedure extracts reviews from both platforms and then the gathered reviews undergo analysis, encompassing descriptive statistics, visualizations, and sentiment analysis. Finally, a procedure is in place to periodically update the database by scraping new product reviews, ensuring its ongoing relevance and accuracy.
3.1 Webscraping data
Web scraping has emerged as a fundamental technique for extracting valuable data from the vast landscape of the World Wide Web. However, as the web continually evolves, the task of efficiently and reliably extracting data becomes more challenging. In the present work three main tools were adopted to scrape product reviews: RainforestAPI and a combination of Scrapy with python using ScrapeOps.
RainforestAPI, an integration layer, is employed to bolster data extraction efforts by facilitating interactions with cloud-based databases and external APIs. This dynamic capability empowers users to access and incorporate real-time, third-party data, enriching the extracted information with context and relevance. It is an API service developed specifically for Web Scraping of Amazon pages (not affiliated or incentivized by Amazon itself). It is optimized for full-browser rendering, Javascript execution and page parsing and it guarantee excellent performances for reliability and scalability at variable costs that scale with use. In the present work it has been adopted for scraping Amazon reviews.
For Walmart reviews scraping a custom Python code has been developed making use of Scrapy and ScrapeOps. Scrapy, a widely adopted open-source web crawling framework, serves as the basis of the developed code. It offers a flexible and powerful platform for spider development, enabling the parsing of websites, the extraction of structured data, and the handling of complex web structures. Scrapy's capacity to manage requests, follow links, and navigate websites systematically empowers users to tailor their data extraction to specific needs. To complement the capabilities of Scrapy, we adopted the ScrapeOps API, a web scraping management platform that enhances the overall process. ScrapeOps provides a centralized environment for orchestrating web scraping tasks, offering a host of valuable features. Specifically IP rotation, Proxy aggregator, User-Agent/Header rotation have been adopted to overcome websites blocks and limitations. This comprehensive framework navigates complex web structures, streamlines scraping task finally providing an automatic procedure to obtain product review data.
3.2 ChatGPT aspect-based sentiment analysis
In this work we propose the adoption of ChatGPT for sentiment analysis: it results in an application of NLP that employs pre-trained GPT model to assess the sentiment of text. Such procedure has been already partially evaluated in comparison with other SA approaches and models in paper as the one proposed by (Wang, Xie, Ding, Feng, & Xia, 2023) and (Belal, She, & Wong, 2023). We used ChatGPT to perform Sentiment Classification (multi-class classification to predict the review overall rating in a scale from 1 to 5) and ABSA (identifying the aspect described inside the review and predicting the polarity associated with such aspect). In particular we built a prompt for ChatGPT asking to extract aspect expressions, related segments and related sentiments from a given text and formatting the output in JSON. To optimize the results, we provide to the bot some example of possible input and related output
A different request is done for each review to analyse. The “rate” field gives the SC on a scale from 1 to 5 while the other field gives the aspects and sentiment together with the segment of the review in which the aspect is described.
3.3 Model based Sentiment analysis
Together with the ChatGPT SA, a model based SA is performed within the tool. We adopted a model available at HuggingFace for SA of Amazon reviews . This model is a BERT-base-multilingual-uncased model that has been fine-tuned specifically for sentiment analysis on product reviews written in six languages: English, Dutch, German, French, Spanish, and Italian. It is designed to predict the sentiment of these reviews in terms of a star rating, ranging from 1 to 5.
According to the author, this pre-trained model is intended for direct use as a sentiment analysis tool for product reviews in any of the six supported languages. Additionally, it can also serve as a foundation for further fine-tuning on related sentiment analysis tasks. It's important to note that the ideal use case for BERT-base is primarily cantered around tasks that leverage the entire sentence, possibly with masking, to make decisions. These tasks typically include sequence classification, token classification, and question answering. In the adopted model, the fine-tuned version of BERT-base was tailored for the specific task of predicting star ratings based on product reviews. It's worth emphasizing that the model's performance and applicability are limited to reviews and products within the Amazon ecosystem or similar. Using this model in other domains or contexts may result in suboptimal performance.
4. Case study application
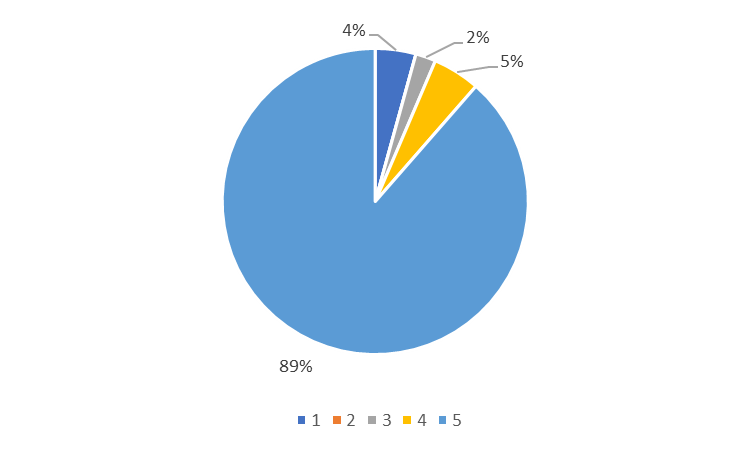
The procedure described at previous sections has been applied to a product of a Microelectronics company. A total amount of 140 reviews have been scraped (100 from Amazon and 68 from Walmart for which 28 did not contain any text reviews but only a rating, leading to a final number of 40 valuable reviews from Walmart) for this case study. The rating distribution for the valuable scraped reviews is reported at Figure 2.
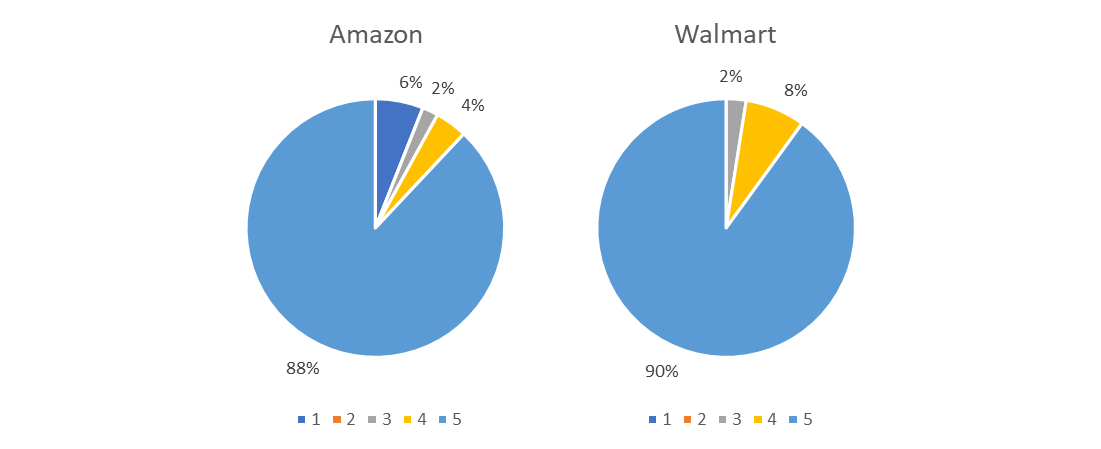
The same visualization is reported at Figure 3 stratified by data Source (whether Amazon or Walmart). As it can be seen from the plots the product presents similar performances independently from the source of the review. For each review the ChatGPT SA and the HuggingFace (HF) model SA have been applied. In both the analysis a Chi-Square test for association has been performed, investigating whether the rating given by the reviewer and the one predicted by the model are associated or not (we adopted a test suitable for categorical variables). We obtain a p-value= 4.97e-17 testing for association between review rating and ChatGPT model prediction, while we obtain a p-value= 1.28e-15 for the association between review rating and HF model prediction. In both cases the association between the rating expressed and the predicted has been confirmed.
We compute the accuracy of the classification given by the two models: once obtained the multiclass confusion matrix (comparing sentiment classification obtained with the model and the actual rating given by the reviewer) we compute the accuracy as the amount of correct classification over the total amount of ratings. This results in an accuracy of 63,7% for ChatGPT SA model and of 85,7% for HF SA model. In this case the state-of-the-art model result to outperform the ChatGPT model in the task of document level sentiment analysis.
Having the information of the date in which the reviews has been published some visualizations concerning the time dimension are available in the developed tool. For example, Figure 4 reports the weekly time series of the average rating expressed in the reviews or predicted by the models. Figure 5 reports, by day, the percentage on the daily total of reviews with each of the 5 ratings. These plots allow practitioners and businesses to check in real time the trend with their product.
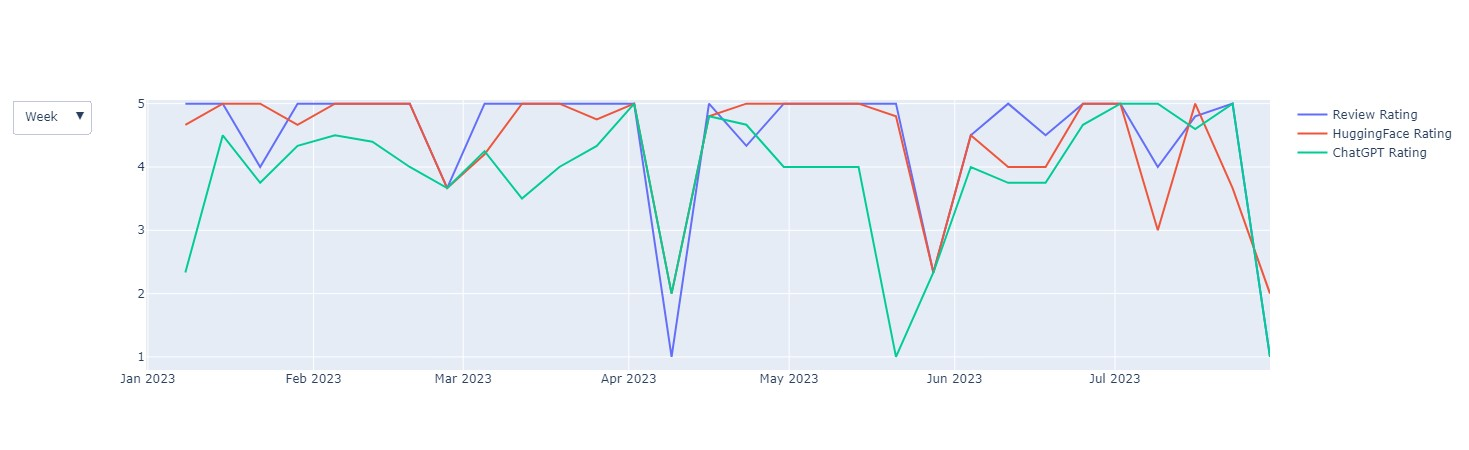
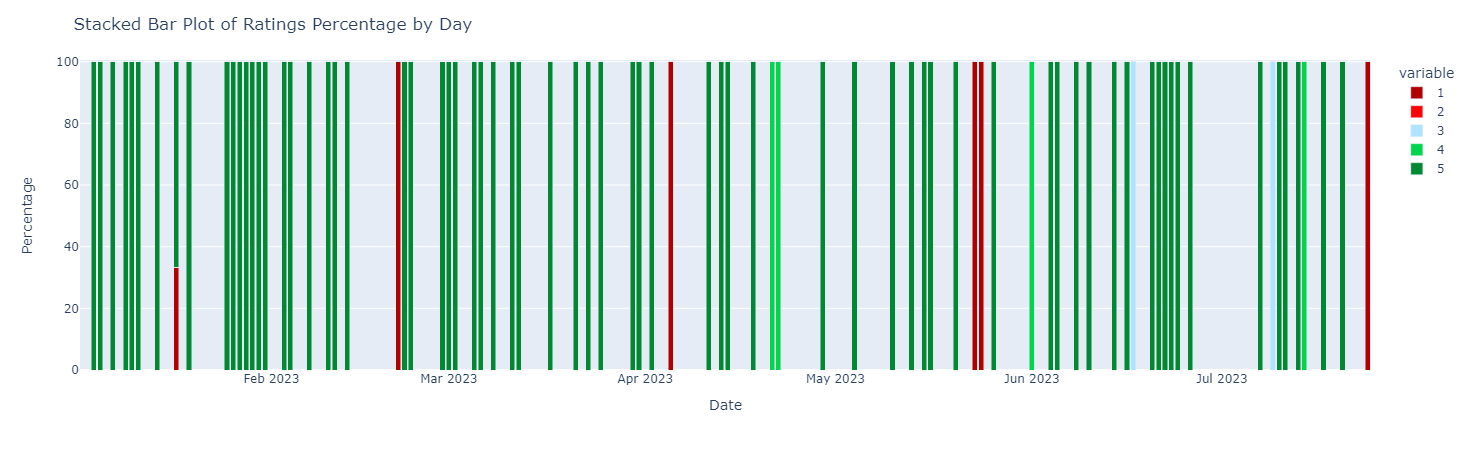
Table 1. Extracted aspects and related sentiment.
|
Aspect |
Positive |
Negative |
Neutral |
N |
|||
|
Aspect 1 |
94 |
93,1% |
6 |
5,9% |
1 |
1% |
101 |
|
Aspect 2 |
22 |
95,7% |
1 |
4,3% |
0 |
0% |
23 |
|
Aspect 3 |
49 |
100% |
0 |
0% |
0 |
0% |
49 |
|
Aspect 4 |
18 |
100% |
0 |
0% |
0 |
0% |
18 |
|
Aspect 5 |
13 |
81,3% |
3 |
18,8% |
0 |
0% |
16 |
|
Aspect 6 |
14 |
93,3% |
1 |
6,7% |
0 |
0% |
15 |
|
Aspect 7 |
8 |
100% |
0 |
0% |
0 |
0% |
8 |
|
Aspect 8 |
9 |
100% |
0 |
0% |
0 |
0% |
9 |
|
Aspect 9 |
0 |
0% |
4 |
100% |
0 |
0% |
4 |
|
Aspect 10 |
3 |
75% |
1 |
25% |
0 |
0% |
4 |
|
Aspect 11 |
4 |
80% |
1 |
20% |
0 |
0% |
5 |
|
Aspect 12 |
5 |
100% |
0 |
0% |
0 |
0% |
5 |
|
Aspect 13 |
2 |
50% |
1 |
25% |
1 |
25% |
4 |
|
Aspect 14 |
0 |
0% |
2 |
66,7% |
1 |
33,3% |
3 |
|
Aspect 15 |
2 |
66,7% |
1 |
33,3% |
0 |
0% |
3 |
|
Aspect 16 |
1 |
33,3% |
2 |
66,7% |
0 |
0% |
3 |
|
Aspect 17 |
3 |
75% |
1 |
25% |
0 |
0% |
4 |
|
Aspect 18 |
4 |
100% |
0 |
0% |
0 |
0% |
4 |
|
Aspect 19 |
1 |
33,3% |
2 |
66,7% |
0 |
0% |
3 |
|
Aspect 20 |
1 |
33,3% |
1 |
33,3% |
1 |
33,3% |
3 |
Finally, the aspect-based SA results are available within the tool. Table 1 report the most frequently extracted aspect for the reviews scraped from both Amazon and Walmart. Please note that the aspects have been anonymized for privacy reason towards the company whose product have been analysed. Together with the aspect that ChatGPT extracted, the number of occurrences in which the sentiment towards the aspect is positive, negative or neutral is available (both as an absolute value and as percentage on the total occurrence of the aspect). The 20 most frequent extracted aspect are reported. Since the ChatGPT prompt asked the model also the segment in which the aspect and its sentiment is available, within the developed tool the review and the segment are available and connected to the extracted aspect and sentiment.
5. Discussion
The proposed web scraping tool allows researchers and businesses to collect a large dataset of product reviews from e-commerce websites, which can be invaluable for various purposes, such as market research, product development, and competitive analysis. The tool provides an efficient means of data collection by systematically retrieving product reviews from these two major e-commerce platforms. However, it is important to acknowledge a significant limitation here, which is the number of reviews that can be scraped. Many websites employ anti-scraping measures and limits the number of reviews are available online, thus limiting the number of data that can be retrieved. This limitation may affect the comprehensiveness of the dataset. At the same time the proposed tool goes beyond mere data collection and delves into sentiment analysis, a crucial aspect of understanding the customer's perspective. This can help businesses and researchers gauge the general customer satisfaction with a product, identify areas for improvement, and track how sentiment changes over time. In particular, in addition to overall sentiment analysis base on the state-of-the-art model and on ChatGPT, the tool also incorporates aspect-based sentiment analysis performed automatically with ChatGPT. The proposed tool for web scraping product reviews, coupled with sentiment analysis and aspect-based sentiment analysis, represents a valuable resource for businesses and researchers aiming to gain insights into consumer preferences, product performance, and market trends.
6. Conclusion
The advent of e-commerce has transformed the way consumers make purchasing decisions. Online marketplaces offer an abundance of product options, and consumers increasingly rely on product reviews to make informed choices. As a result, the analysis of product reviews has become a critical aspect of understanding consumer preferences, product quality, and market trends. This paper introduced a tool developed for web scraping e-commerce product reviews and conducting sentiment analysis, particularly aspect-based sentiment analysis, in an automatic manner.
The automated nature of the tool streamlines data collection and analysis, saving time and resources. However, it's important to note that there are limitations, primarily related to the number of reviews that can be scraped due to anti-scraping measures implemented by these e-commerce platforms.
To overcome this limitation, future research could focus on developing more advanced web scraping techniques or exploring alternative data sources. Despite these limitations, the proposed tool has the potential to provide valuable insights to businesses and researchers, aiding them in making data-driven decisions, enhancing product offerings, and understanding customer sentiments at a deeper level. As the e-commerce landscape continues to evolve, automated tools like the one proposed in this paper will play a crucial role in keeping pace with the growing volume of online product reviews and the ever-changing consumer sentiment.
7. Acknowledgement
Nicoló Biasetton and Luigi Salmaso thanks the MICS. This study was carried out within the MICS (Made in Italy—Circular and Sustainable) Extended Partnership and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR)—MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.3—D.D. 1551.11-10-2022, PE00000004).
Rosa Arboretti thanks MOST. This study was carried out within the MOST—Sustainable Mobility National Research Centre and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR)—MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.4—D.D. 1033 17 June 2022, CN00000023).
This manuscript reflects only the authors’ views and opinions; neither the European Union nor the European Commission can be considered responsible for them.
References
[1] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg e D. Amodei, «Deep reinforcement learning from human preferences,» Advances in neural information processing systems, vol. 30, 2017.
[2] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray e others, «Training language models to follow instructions with human feedback, 2022,» URL https://arxiv. org/abs/2203.02155, vol. 13, 2022.
[3] B. Liu, Sentiment analysis: Mining opinions, sentiments, and emotions, Cambridge university press, 2020. View Article
[4] I. Chaturvedi, E. Cambria, R. E. Welsch e F. Herrera, «Distinguishing between facts and opinions for sentiment analysis: Survey and challenges,» Information Fusion, vol. 44, p. 65-77, 2018. View Article
[5] İ. A. Özen e E. Özgül Katlav, «Aspect-based sentiment analysis on online customer reviews: a case study of technology-supported hotels,» Journal of Hospitality and Tourism Technology, vol. 14, p. 102-120, 2023. View Article
[6] M. Birjali, M. Kasri e A. Beni-Hssane, «A comprehensive survey on sentiment analysis: Approaches, challenges and trends,» Knowledge-Based Systems, vol. 226, p. 107134, 2021. View Article
[7] T. Wilson, J. Wiebe e P. Hoffmann, «Recognizing contextual polarity in phrase-level sentiment analysis,» in Proceedings of human language technology conference and conference on empirical methods in natural language processing, 2005. View Article
[8] A. Meena e T. V. Prabhakar, «Sentence level sentiment analysis in the presence of conjuncts using linguistic analysis,» in Advances in Information Retrieval: 29th European Conference on IR Research, ECIR 2007, Rome, Italy, April 2-5, 2007. Proceedings 29, 2007.
[9] Y. Jo e A. H. Oh, «Aspect and sentiment unification model for online review analysis,» in Proceedings of the fourth ACM international conference on Web search and data mining, 2011. View Article
[10] A. Jurek, M. D. Mulvenna e Y. Bi, «Improved lexicon-based sentiment analysis for social media analytics,» Security Informatics, vol. 4, p. 1-13, 2015.
[11] M. Hu e B. Liu, «Mining and summarizing customer reviews,» in Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004. View Article
[12] S. Bagherzadeh, S. Shokouhyar, H. Jahani e M. Sigala, «A generalizable sentiment analysis method for creating a hotel dictionary: using big data on TripAdvisor hotel reviews,» Journal of Hospitality and Tourism Technology, vol. 12, p. 210-238, 2021. View Article
[13] S. Ruder, P. Ghaffari e J. G. Breslin, «A hierarchical model of reviews for aspect-based sentiment analysis,» arXiv preprint arXiv:1609.02745, 2016. View Article
[14] İ. A. Özen e İ. İlhan, «Opinion mining in tourism: a study on "Cappadocia home cooking" restaurant,» in Handbook of research on smart technology applications in the tourism industry, IGI Global, 2020, p. 43-64. View Article
[15] M. R. D. Ching e R. de Dios Bulos, «Improving restaurants' business performance using Yelp data sets through sentiment analysis,» in Proceedings of the 3rd International Conference on E-commerce, E-Business and E-Government, 2019. View Article
[16] G. Joseph e V. Varghese, «Analyzing Airbnb customer experience feedback using text mining,» Big Data and Innovation in Tourism, Travel, and Hospitality: Managerial Approaches, Techniques, and Applications, p. 147-162, 2019. View Article
[17] J. Kocoń, I. Cichecki, O. Kaszyca, M. Kochanek, D. Szydło, J. Baran, J. Bielaniewicz, M. Gruza, A. Janz, K. Kanclerz e others, «ChatGPT: Jack of all trades, master of none,» Information Fusion, p. 101861, 2023. View Article
[18] Y. Chen e S. Eger, «Transformers go for the LOLs: Generating (humourous) titles from scientific abstracts end-to-end,» arXiv preprint arXiv:2212.10522, 2022. View Article
[19] W. Jiao, W. Wang, J.-t. Huang, X. Wang e Z. Tu, «Is ChatGPT a good translator? A preliminary study,» arXiv preprint arXiv:2301.08745, 2023. View Article
[20] W. Tabone e J. De Winter, «Using ChatGPT for human-computer interaction research: A primer,» Manuscript submitted for publication, 2023. View Article
[21] Ö. Aydın e E. Karaarslan, «OpenAI ChatGPT generated literature review: Digital twin in healthcare,» Available at SSRN 4308687, 2022. View Article
[22] M. M. Amin, E. Cambria e B. W. Schuller, «Will affective computing emerge from foundation models and general ai? A first evaluation on chatgpt,» arXiv preprint arXiv:2303.03186, 2023. View Article
[23] W. Castillo-González, «The importance of human supervision in the use of ChatGPT as a support tool in scientific writing,» Metaverse Basic and Applied Research, vol. 2, p. 29-29, 2023. View Article
[24] I. El Karfi e S. El Fkihi, «An ensemble of arabic transformer-based models for arabic sentiment analysis,» International Journal of Advanced Computer Science and Applications, vol. 13, 2022. View Article
[25] Z. Wang, Q. Xie, Z. Ding, Y. Feng e R. Xia, «Is ChatGPT a good sentiment analyzer? A preliminary study,» arXiv preprint arXiv:2304.04339, 2023.
[26] M. Belal, J. She e S. Wong, «Leveraging ChatGPT As Text Annotation Tool For Sentiment Analysis,» arXiv preprint arXiv:2306.17177, 2023.